Regular readers of Nones Notes Blog know that my brother, Nelson Nones, has lived and worked outside the United States for nearly 25 years – much of that time in East Asia. So naturally I was curious about his perspectives on the spread of the Coronavirus from its epicenter in Wuhan, China, what precautions he is taking in the face of the threat, and his perspectives on how the actions of Asian countries affected by the outbreak may be mitigating the potential effects of the virus.
Here is what Nelson wrote to me in response to my query:
The Coronavirus has not affected my business here in Bangkok to date. I did make a trip to Singapore during the last week of January and to Taiwan during the first week of February, after arriving back in Thailand from the U.S. on January 12th. I haven’t been sick at all – before or since.
However, in an abundance of caution I am keeping myself at home as much as possible, and I have decided not to travel anywhere until the current hullabaloo dies down.
As for the situation here in Thailand, this country is actually the location of the first COVID-19 (Coronavirus) case ever recorded outside Mainland China. This was back on January 13th, just two weeks after China first notified the World Health Organization (WHO) of the new disease, and only two days after China recorded its first COVID-19 death.
The patient here in Thailand was a Chinese woman who had traveled from Wuhan, the epicenter of the pandemic.
Since then, Thailand has recorded 42 additional cases for a total of 43 patients, of whom only one died (on Sunday March 1st), and 31 have recovered. This leaves 11 active cases – all considered mild.
The first case of human-to-human virus transmission within Thailand was recorded on January 16th, affecting a taxi driver. Of the 43 cases confirmed so far, 25 affected Chinese citizens; seven affected Thai citizens with travel histories to China, Japan or South Korea; seven affected Thai citizens who work in the tourism or healthcare industries; and the remaining four were other domestic cases (of which only two potentially represent “community spread”). Thailand’s infection growth factor peaked on January 26th.
Being one of the world’s most popular tourist destinations (especially from China), Thailand has never imposed any travel restrictions, even from China (nor has the U.S. ever imposed any COVID-19 travel restrictions on Thailand), but all arriving international passengers are screened by an initial body temperature check. Those who fail the initial screening are required to disclose their travel histories within the past 14 days, in detail. If they have travelled to or from any affected areas, and exhibit any COVID-19 symptoms, they are immediately quarantined at a specially-designated hospital for isolation and treatment.
Under the circumstances, and considering its geographic proximity to China as well as the normal volume of Chinese tourist travel, I think Thailand’s containment efforts so far have been successful and offer some lessons for the United States. Containment in India, Indonesia and Bangladesh so far is even more impressive (Indonesia reported its first two cases only on March 2nd).
Displayed below is a listing of South, Southeast and East Asian countries, ranked by population (together with the U.S. for comparison purposes), showing the number of cases and deaths reported so far:

* Excludes Diamond Princess cruise liner cases.
Sources:
Case data are from https://www.worldometers.info/coronavirus/#countries
Populations are from https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)
The countries shaded in green, above, are those which did not require advance visas for Chinese citizens holding ordinary passports, prior to the imposition of temporary COVID-19 travel restrictions. These countries were either visa-free or allowed “visa on arrival.”
The countries in red typeface, above, are those which had imposed temporary COVID-19 travel restrictions as of early February 2020. These include “entry bans on Chinese citizens or recent visitors to China, ceased issuing of visas to Chinese citizens and re-imposed visa requirements on Chinese citizens or countries that have responded with border closures with China.” (See https://en.wikipedia.org/wiki/Visa_requirements_for_Chinese_citizens for source data.)
It’s quite clear from the data above that, excluding Mainland China itself, there is little or no correlation between the incidence of COVID-19 cases or deaths and the leniency of a country’s previous or current travel restrictions in so far as Mainland Chinese are concerned.
Indeed, all of the four countries having a higher number of cases than Thailand (Japan, South Korea, Hong Kong and Singapore) required advance visas before the COVID-19 outbreak, and all but one (Hong Kong) had imposed COVID-19 entry bans as of February 2nd.
Conversely, apart from Thailand, the countries which did not require advance visas before the COVID-19 outbreak have averaged fewer than one case per country (although all of them except Cambodia and East Timor had imposed temporary COVID-19 travel bans by February 2nd).
The countries shown in bold typeface above are those which are geographically closest to the COVID-19 epicenter. An average of 570 COVID-19 cases have been reported within each of these 10 countries; only Laos has been immune so far. Conversely, an average of 6 COVID-19 cases have been reported within each of the remaining 26 countries (excluding China itself).
From these data, I’ve drawn the following four generalizations:
- Outside of Mainland China, international travel bans and visa restrictions are not effective tools for controlling the spread of COVID-19 disease within a country.
- Geographic proximity to Mainland China is well-correlated to the historical spread of COVID-19 disease in South, Southeast and East Asia.
- Vigilant screening and disposition of suspected cases is vital to containing the spread of COVID-19 disease, as Thailand’s experience demonstrates.
- Allowing high concentrations of suspected cases to form without treatment, such as Wuhan (China), the Diamond Princess docked at Yokohama (Japan) and Shincheonji church at Daegu (South Korea), is a recipe for disaster.
Of course, the virus and its spread is an evolving narrative, and Nelson’s observations may soon be overwhelmed by new developments. Still, I was somewhat surprised to read that the situation is not quite as dire as the news reporting here in the U.S. would seem to indicate.
Have you heard from overseas friends or colleagues about how they are responding to the Coronavirus outbreak? Please share their perspectives with other readers here.

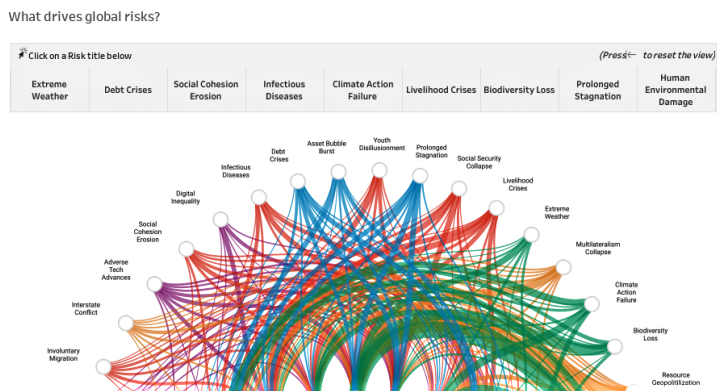 Most people in business and politics have heard of the World Economic Forum (WEF), best known for holding its annual meeting for the world’s glitterati every January in Davos, Switzerland.
Most people in business and politics have heard of the World Economic Forum (WEF), best known for holding its annual meeting for the world’s glitterati every January in Davos, Switzerland.